A brief introduction to computational semantics
As the title says, this post is just a brief introduction to computational semantics. It is by no means comprehensive, and is rather a loosely technical story of my experiences in the field so far. I hope it will inspire you to learn more :)
Some definitions
First, you may be wondering: “What is computational semantics, anyway?”. Wikipedia will tell you:
Computational semantics is the study of how to automate the process of constructing and reasoning with meaning representations of natural language expressions.
But this can be distilled to: “Teaching computers to understand humans.” This challenge is important in a wide variety of applications. From obvious ones, like having Siri actually help you, to more obscure areas, like medical document summarization. Improving how technology understands humans will improve how we interact with it. Computational semantics sets out to tackle this problem from a variety of angles, but for this post I will focus specifically on the challenges and potential solutions to the problem of ‘representing meaning’. To explain why meaning may be difficult to represent, I first have a question for the reader: what is a cat?

The answer you thought of may have been ‘furry four-legged animal that chases mice’, ‘a nuisance’ or something completely different. There are many different correct answers to this question, but if I referred to a cat in conversation, you would understand what I was talking about. Computers can’t process the same information automatically, so we need to define computational models for them to use. One approach could be to just use words, but human language has some difficulties associated with it.
Consider the following three sentences:
- He described her as a genius.
- His description of her: genius
- She was a genius, according to his description.
Most people would agree that these three sentences have the same meaning. Yet, the exact words and their order is different. To a human this difference may seem trivial, but a computer would not be able to pick up on it so easily. A good representation has to be separate meaning from specific wording to properly reflect human communication.
As it turns out, one word can, also, map to multiple meanings. According to different dictionaries either the word run or set have the most definitions (in the Oxford English Dictionary, run has 396, while set has 464 meanings!). You may not be able to produce all of these definitions, but you would understand how a word is being used in different places. If I said ‘that play ran way too long’, you would understand that the play was not running somewhere on two legs. For a computer this distinction is not so obvious, but how are we able to pick the right meaning out of hundreds?
Consider three new sentences, all of which use the word run:
- Truthfully, cats run the show at my house.
- The birds observed the water run peacefully in the river.
- Somebody told me that your code just does not run.
These three sentences use different definitions of the word run, but we can tell them apart because of the context in which they are used. In the first sentence, run is used with the words the show; those two words indicate that run is being used to mean “in charge”. In the second sentence, the subject of run is water; this cues us to the “flow quickly” meaning of water. Finally, your code indicates a particular definition of run as well.

This context, the words surrounding the word in question, is crucial for humans to be able to distinguish between meanings of words, and it will be important for the computer representations.
Representing meaning with words faces at least two challenges: different syntaxes mapping to the same meaning, and the same word mapping to multiple meanings. There are many other challenges of language that representations have to resolve, but for now let’s look at some solutions that have been implemented.
Approach 1: FrameNet
To understand the first approach, we need to take a step back to psychology and the concept of framing. Read the following two sentences:
Mary was invited to Jack’s party. She wondered if he would like a kite.
Now, answer the following question: What was the kite for?
You probably thought of the answer right away (It was a present for Jack). While this task may have seemed trivial, it is actually a testament to the abilities of the human brain. No words mentioning ‘presents’ or ‘gifts’ appear in the sentences, but we immediately made the connection! This example was first introduced by Marvin Minsky in 1970s AI literature as the ‘birthday party frame’, as an example of framing. This concept suggests that different experiences invoke frames, structures that represent related roles, and that we use these frames to understand the world around us. In the example above, the words invited and party evoked a birthday party frame. This frame may have roles like ‘guest’, ‘host’, ‘gift’ and etc., and our brains can fill this information in accordingly.
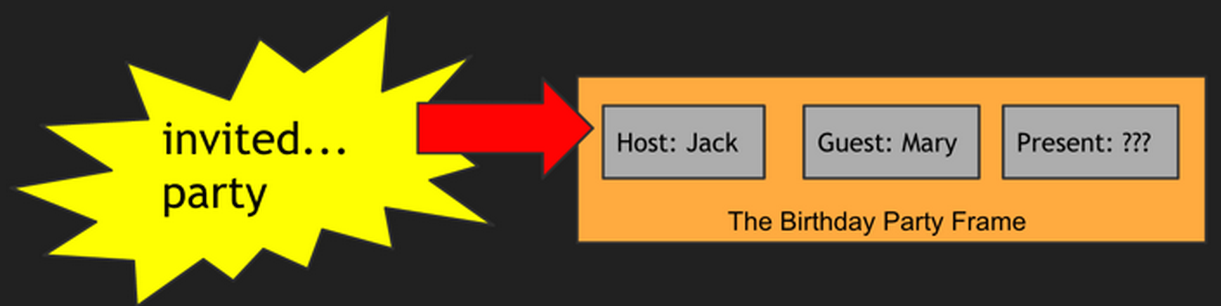 Thus we are able to connect the word ‘kite’ to ‘gift’, without the later word appearing in the sentence. While in the current example framing was used in the context of language, the idea can be extended to other experiences. Frame Semantics extends this concept to suggest that we understand words in terms of the context they appear in. For example, the concept of ‘buying’ would not make sense, if we did not have a concept of ‘buyer’, ‘seller’, ‘monetary exchange’ and etc.
Thus we are able to connect the word ‘kite’ to ‘gift’, without the later word appearing in the sentence. While in the current example framing was used in the context of language, the idea can be extended to other experiences. Frame Semantics extends this concept to suggest that we understand words in terms of the context they appear in. For example, the concept of ‘buying’ would not make sense, if we did not have a concept of ‘buyer’, ‘seller’, ‘monetary exchange’ and etc.

FrameNet is a database that attempts to record these frames in English. It consists of entries that have:
- Frame - the general concept involved
- Frame Element - common roles or knowledge associated with the frame
- Lexical Units - words that evoke the frame
These frames can then be used to represent sentences. The sentence ‘The cats grill burgers on an open fire.’ would be represented as:
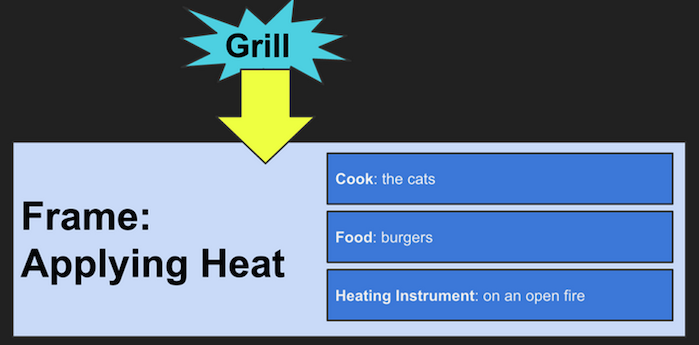
In this example, ‘grill’ is the lexical unit that invokes the frame of ‘applying heat’. ‘Cook’, ‘Food’ and ‘Heating Instrument’ are the frame elements that represent relationships involved in applying heat. This sentence described a physical action, but frames can be used to represent abstract ideas as well. For example, ‘the cat wants to go’ can be expressed with the frame:

FrameNet is just a database of concepts, but additional systems have been developed to convert English to this representation and do additional processing with it. You can learn more about it on FrameNet’s website!
This representation is useful because it separates meaning from syntax and reflects psychology. However, it can be hard to manipulate or extend, because all the Frames have to be defined by humans. Currently, the database contains 10,000 different frames, but many other concepts exist, and new ones will surface as language and society evolve. Next, we look at an approach that tries to resolve this constraint by modeling relationships in a more generic fashion.
Approach 2: Abstact Meaning Representation
Abstract Meaning Representation, or AMR, models meaning through relationships between concepts, but instead of creating specific frames for different situations, it represents the ‘frame elements’ as arguments to a core concept. In its simplest form, a concept (typically an action) will have associated roles ARG0 and ARG1 which are filled by the subject and object respectively. These relationships are represented as a directed graph, where the concepts are nodes, and arguments to a concept are children nodes in the graph. Other arguments such as ‘time’, ‘location’ and ‘manner’ encode additional information that can occur in many situations.
Consider the following graph associated with the sentence ‘the cat wants to go’:
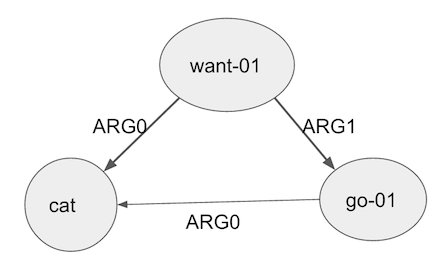
The frame associated with this sentence was ‘desire’ or wanting. This concept is still at the center of the representation, expressed through the root node of ‘want-01’. The frame elements were ‘experiencer’ and ‘event’; here these relationships are represented by the ‘ARG0’ and ‘ARG1’. Thus, we are able to encode similar information with AMR without defining the specific relationships to the word ‘want’. This AMR represents one new piece of information through the edge between ‘go’ and ‘cat’; the edge tells us that it is the cat that will be doing the going. We were not able to show this information in the FrameNet representation which showcases the flexibility of the second approach.
In AMR, words are mapped to concepts (in the first example ‘want-01’ is one definition of ‘want’) to distinguish between diffent meanings. Although, the concepts still need to be defined, the process for introducing new concepts is simpler than the one for introducing frames.
AMR is flexible, but it can be difficult to use in many applications. In particular, converting English into this format poses a tricky challenge. Over the past year, I researched improving one such parser - JAMR. My work focused on mapping words to concepts, and I ran into roadblocks with available labeled data. In particular, for words with multiple meanings that mapped to multiple concepts, we did not always have sufficient examples in the training data of each such mapping to automate the process. Although the corpus of English sentences labeled with AMR is growing, it is not yet large enough for many tasks in the field.
Generic relationships may be powerful in certain situations, but at other times the specific relationships found in FrameNet may be useful. For example, if we want to represent information about an earthquake, we may want to specifically represent its ‘magnitude’ and ‘epicenter’. New versions of AMR may incorporate this information, but so far the two formats represent the compromise between flexibility and representing specific details.
Approach 3: Distributional Semantics
So far, we have looked at representations that have been tailored toward shuman readability. While this may be valuable for understanding how the computer processes things, it is not necessary for many applications. Distributional semantics takes advantage of this fact and suggests that language can be represented as distributions or vectors of numbers. This approach relies on a key hypothesis:
Words with similar distributions have similar meanings
This property makes vector representations meaningful because it makes them capture how different words relate. There are different ways to create such distributions for words, but the common way is to use the context of words near the target word. Frame Semantics suggested that we understand words through their relationships with other words, and a distributional approach allows us to capture all such words. For example, if we take a large set of documents and represent each word in terms of which words it co-occurs with in sentences, we may get a vector for the word ‘cat’ that looks like this:

and this different one for the word dog:

The word cat co-occurs more often with ‘meow’, while the word dog co-occurs more often with ‘bone’. Of course, real data may not show such elegant trends; counting co-occurrences by sentence would capture a lot of noise and extraneous information. Finding the right context to use is one of the main challenges of this approach, but it has still proven to be effective in a variety of applications.
The main advantage of using vectors is the new access to mathematical operations. Given two word vectors, you could tell how similar the words are based on the cosine between their vectors. Many other linear algebra operations can be applied as well, allowing us to not only represent meaning, but also manipulate it.
While this approach may be powerful for individual words, it has no-predefined mechanism for representing relationships between words. Although, we can come up with vectors for ‘cat’, ‘want’ and ‘go’, we can not combine them to represent ‘the cat wants to go’ as naturally as we did in FrameNet or AMR. There is ongoing research about finding meaningful methods for combining the vectors, but they have not yet reached the sophistication of the other approaches.
Concluding Thoughts
In this post, I went over three approaches for representing meaning. Each has its strengths and weaknesses, and each may be appropriate for different applications. At the beginning of this post, I went over two challenges of using words: difference sentences having the same meaning and words having multiple meanings. FrameNet and AMR are able to tackle the first challenge. For example, the following AMR
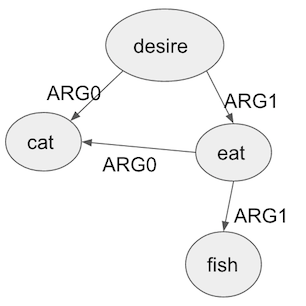
can be used to represent the sentences:
- The cat wants to eat the fish
- The cat’s desire is to eat fish
- Eating fish is what the cat desires
and many others. In distributional semantics, there is not yet a specific way to model relationships between words, so this specific challenge does not apply.
The problem of identifying different meanings of words is handled both by AMR and FrameNet, which uses different concepts (i.e run-01, run-02…) to denote the different senses. Similarly, FrameNet can employ different frames for different meanings of the same word. However, when converting to this format, picking the right concept for the context remains difficult.
Overall, this is an on-going field of research, and some of the big breakthroughs are yet to come. However, I have some general take-aways which may apply beyond this specific problem:
Human language is silly: From the beginning of this post, I pointed out the many ways human language is complicated. We can distinguish different meanings of the same word, map different sentences to the same meaning and do so much more. Yet, the fact that our brains can deal with this complicated mess indicates that meaning has structure, and it is up to us to figure out how we can represent it digitally.
There exists a compromise between human-readability and data availability: AMR and FrameNet representations can be easily understood by humans, but they also require a lot of human-annotated data to work with. Distributional semantics, on the other hand, may not need annotated examples but also can not be understood by humans. A compromise between these two sides can be reached based on the specific needs of an application.
Context is key: Context first came up when we were distinguishing meanings of the word run, and it has come up in some form in every representation. Surrounding information may help us understand language, but it can also be crucial in many other fields. Considering the context may be crucial for us to understand what is going on with data and with the world.
If I’ve sufficiently whet your appetite and you want to learn more, here are some good places to get started:
- General Introduction to Frames
- FrameNet website
- AMR website
- Survey of AMR
- Introduction to Vector Space Models/Distributional Semantics