How to ask a question (automatically)
This post is based on the final project in CMU’s 11-411 (Introduction to Natural Language Processing). It represents an approach we tried, not as a definitive guide on this topic. This was a group project, so I have to give much of the credit to my partner Connell Donaghy!
You probably have heard of question-answering systems: they take in a natural language question and produce an answer, much like a human would. IBM’s Watson, a notable example, even beat former champions at Jeopardy. In this post, I dive into the opposite side: taking in a text or a sentence and outputting intelligent questions about it.

While this task may seem silly (afterall we want computers to solve all problems), it has several interesting applications. First, it can we used for automatically creating data to train question-answering systems. Creating a large human-generated data set for this task may be tedious and unpractical; furthermore, some studies suggest that humans may not be very skilled at asking good questions. Since large and diverse data sets often help create better systems, question-generation can come to the rescue.
More ambitiously, question generating can be incorporated in educational technology. For example, it could generate random questions based on a reading assignment, to verify that students understood it. More generally, question-generation can be used in any intelligent-tutoring system. This paper from MIT, uses this technology to help students learning Mandrin Chinese. While the area is not currently very popular, it has a lot of exciting potential.
Overview
Now that I have convinced you to read on, let’s see how it is done. This guide will focus on asking factual questions from one sentence. Given the sentence:
We would want to generate questions like:
- Was Hamilton nominated for 16 Tonys in 2016?
- What was nominated for 16 Tonys in 2016?
- What was Hamilton nominated for in 2016?
- When was Hamilton nominated for 16 Tonys?
All of these questions can be answered by reading the sentence; they don’t ask for opinions (Did Hamilton deserve the nominations?) or additional analysis (Why was Hamilton nominated for so many Tonys?). Specifically, given a wikipedia article (like the one on Hamilton), we would like to generate N grammatical, reasonable and interesting questions about it. Reasonable questions can be answered by reading the article, and interesting questions are difficult to answer by simple pattern matching on the article.
Our approach created questions for each individual sentence, then ranked them based on fluency and interestingness, and returned the top N of them. To explain how we went from as sentence to a set of question, I first go over some background.
Dependency trees
In NLP, it is useful to represent sentences as data structures, because it allows us to process them more easily. One common way is using trees, which are inspired by syntax and formal grammars. In short, we can use trees that show how different parts of the sentence relate to each other. In dependency parsing, the tree edges represent how words relate to the “main” word of a clause relates to the other words. Common ones include the relationship between a verb and its subjet or object. Consider the following tree for the sentence:
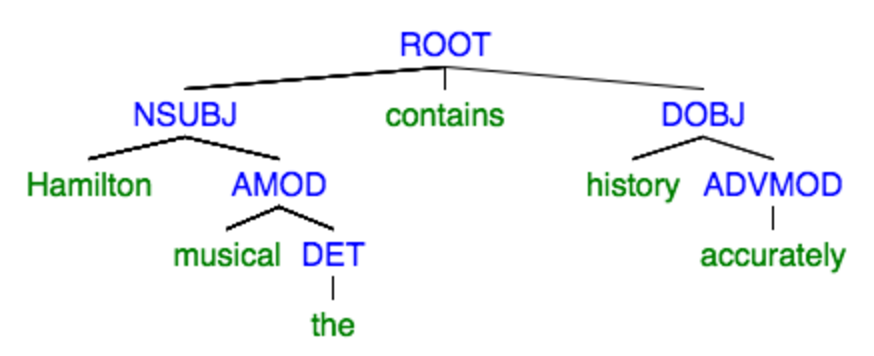
The leaf that is a direct child of a node represents the head word of the clause. Thus, the main word is the verb ‘contains’, and the head of the subject clause (NUBJ) is Hamilton. DOBJ stands for the direct object clause, ‘MOD’s are various modifiers; all the relationships are defined in this manual.
The process repeats, organizing every word into a sub-tree. To extract the sentence, we attached numbers to the words representing their initial position (but this aspect tends to be implementation specific). For our project, we acquired dependency parses of sentences using Stanford CoreNLP which provides a robust implementation.
Creating questions
The dependency tree structure gives us a convinient format for creating questions. First, observe that many sentences can be broken down into the form ‘SUBJECT does ACTION to OBJECT’; there are many exceptions but we can extend them from this basic format. With this format in mind, we can create the following types of factual questions:
- Questions about the subject: Who did the ACTION to the OBJECT?
- Questions about the object: What did SUBJECT do the ACTION to?
- Questions about the time or location: When/Where did SUBJECT do ACTION?
- Questions about the action: What did the SUBJECT do to the OBJECT?
- Questions about manner/description: How did SUBJECT do the ACTION?
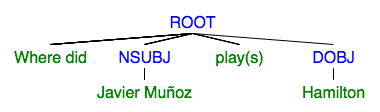
We did not have time to handle the last two types, because the steps to create them can not be easily generalized. But, for the first three, we can manipulate the tree with simple rules. Consider the following sentence and its tree:
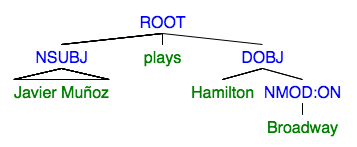
Observe that the tree has node labeled NSUBJ. If we replace its leaf with ‘Who’, then we will get the question: ‘Who plays Hamilton on Broadway’. Similarly, if we remove the DOBJ node entirely and add ‘Who does’ to the beginning of the sentence, we will get the question: ‘Who does Javier Muñoz play’.
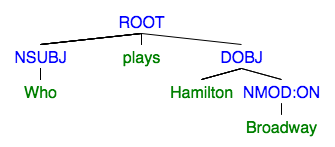
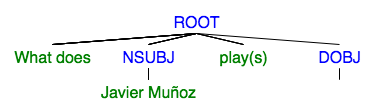
When/Where questions take a little more work, because they aren’t conviniently labeled. To get this information, we rely on prepositional clauses, which can be identified by the ‘NMOD’ label. Once we find such a clause, we need to figure out if it relates to time, a location or something else entirely, the process is detailed in the next section. Assuming we have this information, we can remove this subtree and add “When/Where did” to the beginning, creating the final kind of question.
The conversion process requires several grammatical manipulations (like changing the verb to simple present tense), but overall it really highlights the strengths of dependency parsing.
Several times in the above process, we needed to know the ‘type’ of the entity we were replacing. This information allows us to know whether a Subject and Object question should start with ‘What’ or ‘Who’, and when we can create a ‘Where’ or ‘When’ question. Named Entity Recognition (NER) comes to the rescue; this process finds named entities (essentially proper nouns) and labels them with a category like person, organization, time, location etc. Stanford’s CoreNLP has a contains a great implementation, so we were easily able to access this information and resolve ambiguity.
The simple case?
There is one, seemingly easy, kind of question that I have not covered yet - the ‘yes’ or ‘no’ question. The ‘yes’ case is straightforward. We can take the original sentence, add ‘Did’ to the front and convert the main verb to its simple form:
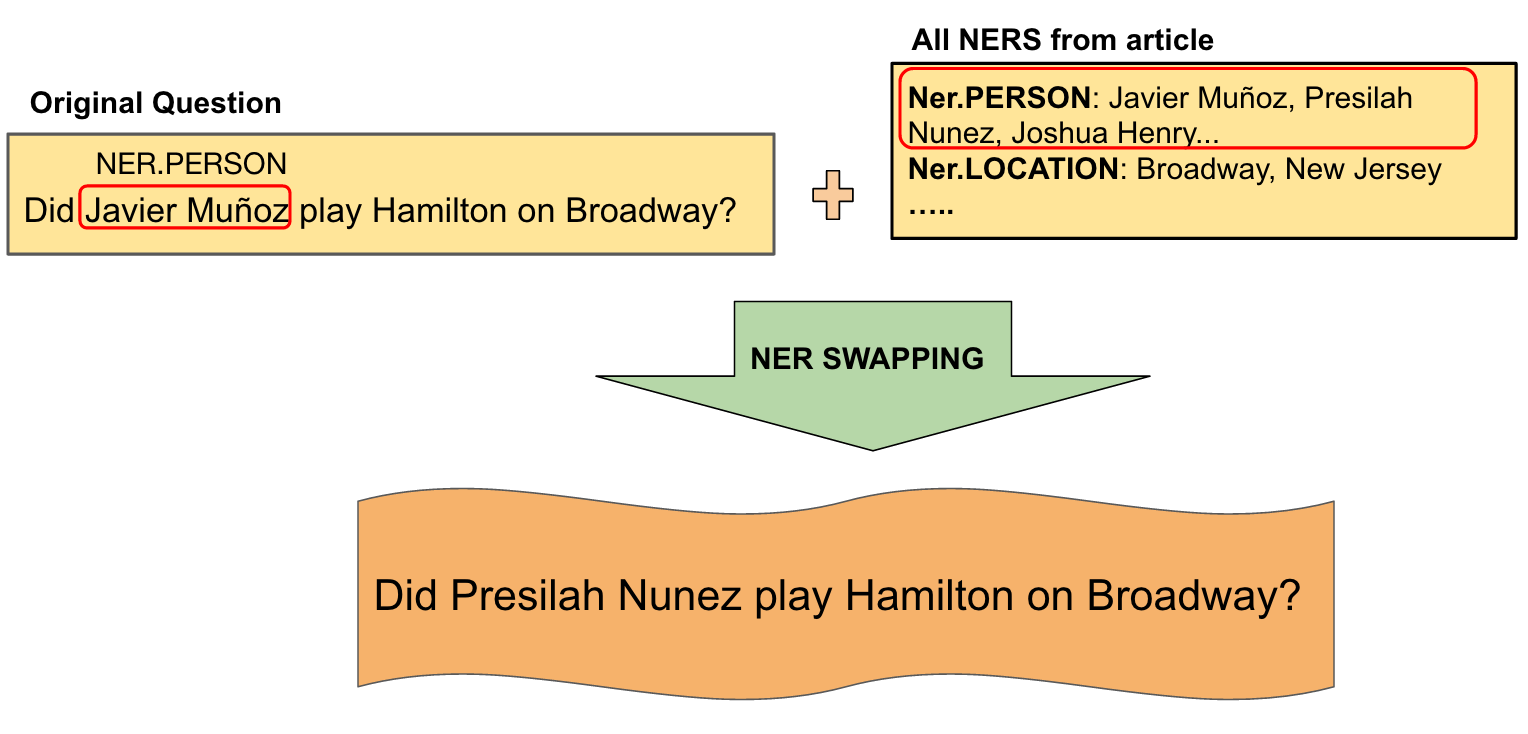
The ‘no’ case is tricker; it requires us to make a false statement about the sentence. Simple negation (Did Javier Muñoz not play Hamilton on Broadway?) does not produce very interesting questions and can be difficult to mention grammatically. Instead, we can change on of the other entities in the sentence to make the factoid false. For example, if we replace ‘Javier Muñoz’ with a different person, the statement will no longer be true. However, we need to come up with a reasonable alternate name: using ‘Anastassia’ may make the statement false, but it will be off-topic in the context of the article.
Luckily, we have access to the entire article that the sentence came from, so we can another word with the same NER category and swap it in. Presilah Nunez is the name of another actor in Hamilton, so, we may produce the question ‘Did Presilah Nunez play Hamilton on Broadway?’ to which the answer is ‘no’. We call this process NER Swapping, and it has allowed us to produce a number of believable but false questions about the article.
Simplifying trees
The process in the previous section is fairly simple, but unfortunantely many sentences are not so simple. For example, if the program took in the sentence:
It would output the question:
While technically grammatical, a more natural question would be:
<div align=”center” style=”margin-bottom: 2rem”;> Who in the presidential elections of 1800 defeated John Adams? </div>
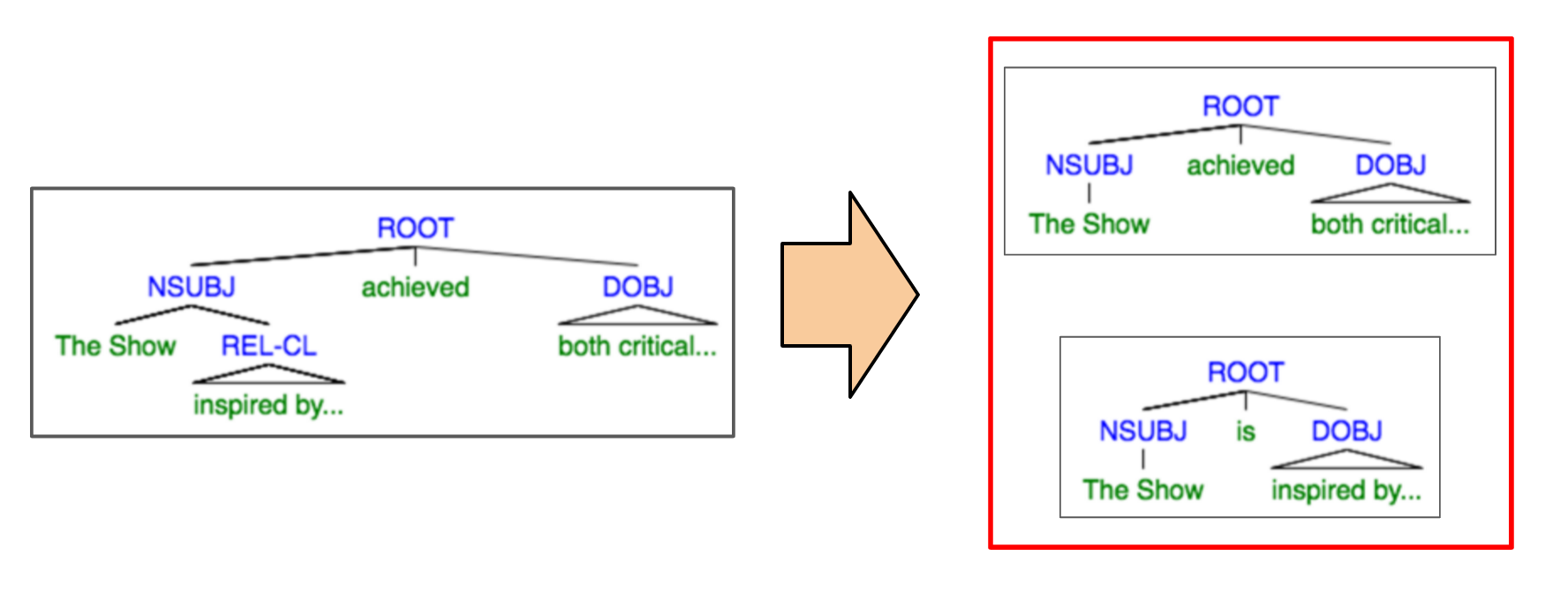
In order to produce simpler questions, we decided to simplify the original sentence.Inspired by this paper, we employ a two step process. First, removing clauses that do not contain information critical to the factoid. Second, producing additional sentences using these extra clauses. Given the sentence:
<div align=”center” style=”margin-bottom: 2rem”;> The show, inspired by the 2004 biography ‘Alexander Hamilton’ by historian Ron Chernow, achieved both critical acclaim and box office success. </div>
we produce the new sentences:
- The show achieved both critical acclaim and box office success.
- The show is inspired by the 2004 biography’Alexander Hamilton’ by historian Ron Chernow
which lead to a number of more concise questions. To achieve such results, we turn again to the dependency trees. Additional information often lives in relative clauses, which are contained in their own subtree. Thus, it is straightforward to remove them, without altering the structure of the remaining sentence. To create the additional sentences, we connect the relative clause to the head word it is refering to with ‘is’.
In reality, this process is more complicated than pictured. For example, the head word that the relative clause is refering to may be hard to identify. In our system, we limited the procedure to only noun clauses. Other aspects of dependency trees are difficult to handle manually, as well; however, tools like Tsurgeon may help make this process more flexible in the future.
Final Steps and Thoughts
With the simplification and generation process explained, we are ready to generate questions. The final step of our project was to rank the questions and return the best ones. We rank questions based on how fluent and reasonable they are. To rate fluency, we use a custom language model based on an existing database of questions. For the reasonable metric, we want to rank highly questions that can be answered by reading the article. So, we filter our questions with pronouns (Who is he?) and bias towards questions with named entities (Who is Hamilton?).
While simple, our process lays a solid foundation for future question generation work. As a final example, given the article on Hamilton, our systems generated the awesome questions:
- Who reminds Hamilton of Philip’s ninth birthday?
- When did The show transfer to Broadway at the Richard Rodgers Theatre?
- Did Barker remind Hamilton of Philip’s ninth birthday?
- Did Eliza remind Hamilton of Edwards’s ninth birthday?
- Who broke the story of Hamilton’s infidelity?
- When is Hamilton chosen as a delegate to the Constitutional Convention?
- Did journalist James Evan break the story of Hamilton’s infidelity?
Judge these for yourself. Personally, I feel that we sucessful in making grammatical questions, yet limited in making them diverse. MEH, dunno.
Overall, I think this project underscores how difficult natural language generation can be. By limiting ourselves to only a few question types, we were fairly sucessful. Yet, hundreds on hand-written rules, it becomes difficult to handle the different variations stemming from things like tenses to word senses, while still generating interesting questions. What methods, in your opinion, will help us over come these challenges?